The korelační koeficient ve statistikách je to ukazatel, který měří tendenci dvou kvantitativních proměnných X a Y mít mezi nimi lineární nebo proporcionální vztah.
Obecně platí, že páry proměnných X a Y jsou dvě charakteristiky stejné populace. Například X může být výška člověka a Y jeho hmotnost..
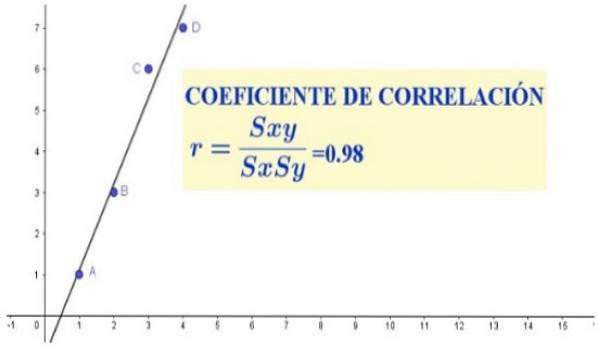
V tomto případě by korelační koeficient indikoval, zda v dané populaci existuje trend proporcionálního vztahu mezi výškou a hmotností..
Pearsonův lineární korelační koeficient je označen písmenem r malá písmena a jeho minimální a maximální hodnoty jsou -1, respektive +1.
Hodnota r = +1 by znamenala, že množina párů (X, Y) je dokonale zarovnaná a že když X poroste, Y poroste ve stejném poměru. Na druhou stranu, pokud by se stalo, že r = -1, sada párů by byla také dokonale zarovnaná, ale v tomto případě, když X roste, Y klesá ve stejném poměru.
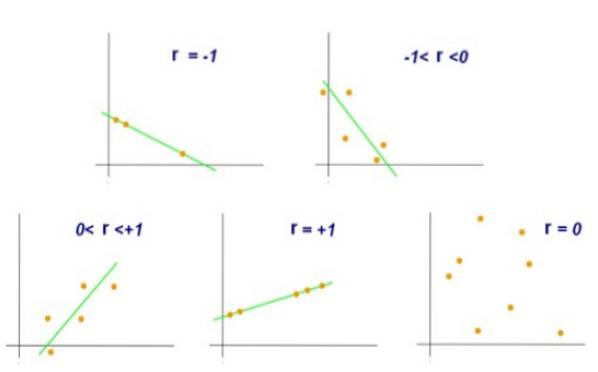
Na druhou stranu by hodnota r = 0 znamenala, že mezi proměnnými X a Y neexistuje lineární korelace. Zatímco hodnota r = +0,8 by naznačovala, že páry (X, Y) mají tendenci se shlukovat na jedné straně a další z určité postupky.
Vzorec pro výpočet korelačního koeficientu r je následující:
Lineární korelační koeficient je statistická veličina nalezená ve vědeckých kalkulačkách, většině tabulek a statistických programech..
Je však vhodné vědět, jak se používá vzorec, který jej definuje, a za tímto účelem se zobrazí podrobný výpočet prováděný na malém souboru dat.
A jak bylo řečeno v předchozí části, korelační koeficient je kovarianční Sxy dělený součinem směrodatné odchylky Sx pro proměnné X a Sy pro proměnnou Y.
Kovarianční Sxy je:
Sxy = [Σ (Xi -
Kde součet jde od 1 do N párů dat (Xi, Yi).
Pro svou část je směrodatná odchylka pro proměnnou X druhá odmocnina rozptylu datové sady Xi, s i od 1 do N:
Sx = √ [Σ (Xi -
Podobně standardní odchylka pro proměnnou Y je druhá odmocnina rozptylu datové sady Yi, s i od 1 do N:
Sy = √ [Σ (Yi -
Abychom podrobně ukázali, jak vypočítat korelační koeficient, vezmeme následující sadu čtyř párů dat
(X, Y): (1, 1); (2.3); (3, 6) a (4, 7).
Nejprve vypočítáme aritmetický průměr pro X a Y takto:
Poté se vypočítají zbývající parametry:
Sxy = [(1 - 2,5) (1 - 4,25) + (2 - 2,5) (3 - 4,25) + (3 - 2,5) (6 - 4,25) +….…. (4 - 2,5) (7 - 4,25) ] / (4-1)
Sxy = [(-1,5) (- 3,25) + (-0,5) (- 1,25) + (0,5) (1,75) +… .
…. (1,5) (2,75)] / (3) = 10,5 / 3 = 3.5
Sx = √ [(- 1,5)dva + (-0,5)dva + (0,5)dva + (1,5)dva) / (4-1)] = √ [5/3] = 1.29
Sx = √ [(-3,25)dva + (-1,25)dva + (1,75)dva + (2,75)dva) / (4-1)] =
√ [22,75 / 3] = 2.75
r = 3,5 / (1,29 * 2,75) = 0,98
V datovém souboru předchozího případu je pozorována silná lineární korelace mezi proměnnými X a Y, která se projevuje jak v rozptylovém grafu (znázorněném na obrázku 1), tak v korelačním koeficientu, který přinesl hodnotu velmi blízkou jednotě.
Pokud je korelační koeficient blíže 1 nebo -1, tím větší smysl má přizpůsobení dat řádku, výsledek lineární regrese..
Lineární regresní přímka se získá z Metoda nejmenších čtverců. ve kterém jsou parametry regresní přímky získány z minimalizace součtu druhé mocniny rozdílu mezi odhadovanou hodnotou Y a Yi N dat.
Na druhou stranu parametry a a b regresní přímky y = a + bx, získané metodou nejmenších čtverců, jsou:
* b = Sxy / (Sxdva) Pro svah
* a =
Připomeňme, že Sxy je kovariance definovaná výše a Sxdva je rozptyl nebo čtverec směrodatné odchylky definované výše.
Korelační koeficient se používá k určení, zda existuje lineární korelace mezi dvěma proměnnými. Je použitelné, když proměnné, které mají být studovány, jsou kvantitativní a navíc se předpokládá, že sledují normální rozdělení typu..
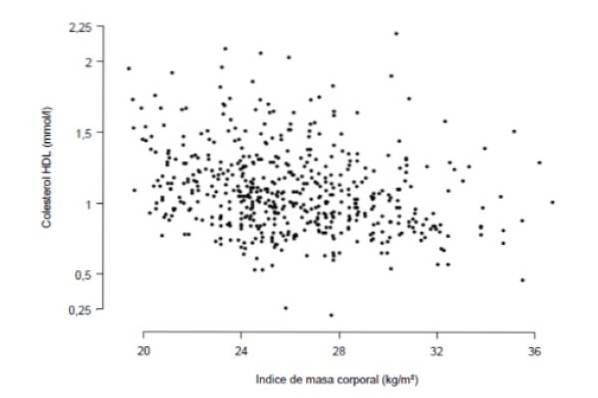
Níže uvádíme ilustrativní příklad: měřítkem míry obezity je index tělesné hmotnosti, který se získá vydělením hmotnosti člověka v kilogramech na druhou ve stejné výšce v jednotkách metrů na druhou.
Chcete vědět, zda existuje silná korelace mezi indexem tělesné hmotnosti a koncentrací HDL cholesterolu v krvi, měřeno v milimolech na litr. Za tímto účelem byla provedena studie s 533 lidmi, která je shrnuta v následujícím grafu, kde každý bod představuje údaje o osobě.
Pečlivé sledování grafu ukazuje, že existuje určitý lineární trend (ne příliš výrazný) mezi koncentrací HDL cholesterolu a indexem tělesné hmotnosti. Kvantitativním měřítkem tohoto trendu je korelační koeficient, který se pro tento případ ukázal jako r = -0,276.



Zatím žádné komentáře