The stupně svobody ve statistikách je to počet nezávislých složek náhodného vektoru. Pokud má vektor n komponenty a tam jsou p lineární rovnice, které se vztahují k jejich složkám, pak stupeň svobody je n-p.
Koncept stupně svobody Také se objevuje v teoretické mechanice, kde zhruba odpovídá dimenzi prostoru, kde se částice pohybuje, minus počet vazeb..
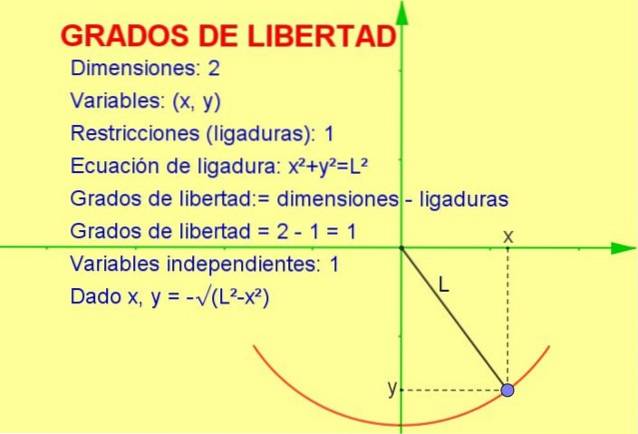
Tento článek pojednává o konceptu stupňů volnosti aplikovaných na statistiku, ale mechanický příklad je snadnější vizualizovat v geometrické formě.
Rejstřík článků
V závislosti na kontextu, ve kterém se používá, se způsob výpočtu počtu stupňů volnosti může lišit, ale základní myšlenka je vždy stejná: celkové rozměry minus počet omezení.
Uvažujme oscilační částici vázanou na strunu (kyvadlo), která se pohybuje ve svislé rovině x-y (2 rozměry). Částice je však nucena pohybovat se po obvodu poloměru rovnajícího se délce akordu.
Vzhledem k tomu, že se částice může pohybovat pouze na této křivce, počet stupně svobody je 1. To je vidět na obrázku 1.
Způsob výpočtu počtu stupňů volnosti spočívá v rozdílu počtu dimenzí minus počet omezení:
stupně volnosti: = 2 (rozměry) - 1 (ligatura) = 1
Další vysvětlení, které nám umožňuje dospět k výsledku, je následující:
-Víme, že poloha ve dvou dimenzích je reprezentována bodem souřadnic (x, y).
-Ale protože bod musí splňovat rovnici obvodu (xdva + Ydva = Ldva) pro danou hodnotu proměnné x je proměnná y určena uvedenou rovnicí nebo omezením.
Proto je pouze jedna z proměnných nezávislá a systém ji má jeden (1) stupeň volnosti.
Pro ilustraci, co tento pojem znamená, předpokládejme vektor
X = (x1, Xdva,..., Xn)
Co představuje vzorek n normálně distribuované náhodné hodnoty. V tomto případě náhodný vektor X mít n nezávislé komponenty, a proto se říká, že X mít n stupňů volnosti.
Nyní vytvořme vektor r odpadu
r = (x1 -
Kde
Takže součet
(X1 -
Je to rovnice, která představuje omezení (nebo vazbu) na prvky vektoru r zbytků, protože pokud je známo n-1 složek vektoru r, rovnice omezení určuje neznámou složku.
Proto vektor r dimenze n s omezením:
∑ (xi -
Mít (n - 1) stupňů volnosti.
Opět platí, že výpočet počtu stupňů volnosti je:
stupně volnosti: = n (rozměry) - 1 (omezení) = n-1
Variance sdva je definován jako průměr druhé mocniny odchylek (nebo zbytků) vzorku n údajů:
sdva = (r•r) / (n-1)
kde r je vektor zbytků r = (x1 -
sdva = ∑ (xi -
V každém případě je třeba poznamenat, že při výpočtu střední hodnoty čtverce zbytků se dělí (n-1), nikoli n, protože jak je uvedeno v předchozí části, počet stupňů volnosti vektor r je (n-1).
Pokud pro výpočet rozptylu byly vyděleny n místo (n-1) by výsledek měl zkreslení, které je velmi významné pro hodnoty n pod 50 let.
V literatuře se varianční vzorec také objevuje s dělitelem n místo (n-1), pokud jde o rozptyl populace.
Ale množina náhodné proměnné zbytků, představovaná vektorem r, Ačkoli má rozměr n, má pouze (n-1) stupňů volnosti. Pokud je však počet dat dostatečně velký (n> 500), oba vzorce konvergují ke stejnému výsledku.
Kalkulačky a tabulky poskytují obě varianty rozptylu a směrodatnou odchylku (což je druhá odmocnina rozptylu).
Naše doporučení, s ohledem na zde prezentovanou analýzu, je vždy zvolit verzi s (n-1) pokaždé, když je nutné vypočítat odchylku nebo směrodatnou odchylku, aby se zabránilo zkresleným výsledkům..
Některá rozdělení pravděpodobnosti v spojité náhodné proměnné závisí na volaném parametru stupeň svobody, je případ chí kvadrát distribuce (χdva).
Název tohoto parametru pochází přesně ze stupňů volnosti podkladového náhodného vektoru, na který se toto rozdělení vztahuje.
Předpokládejme, že máme g populací, ze kterých se odebírají vzorky o velikosti n:
X1 = (x11, x1dva,… X1n)
X2 = (x21, x2dva,… X2n)
... .
Xj = (xj1, xjdva,… Xjn)
... .
Xg = (xg1, xgdva,… Xgn)
Populace j co má průměr
Standardizovaná nebo normalizovaná proměnná zji je definován jako:
zji = (xji -
A vektor Zj je definován takto:
Zj = (zj1, zjdva,..., zji,..., zjn) a sleduje standardizované normální rozdělení N (0,1).
Takže proměnná:
Q = ((z11 ^ 2 + z21^ 2 +…. + zg1^ 2),…., (Z1n^ 2 + z2n^ 2 +…. + zgn^ 2))
následujte rozdělení χdva(g) volal chi square distribuce se stupněm volnosti G.
Chcete-li testovat hypotézy založené na určité sadě náhodných dat, musíte znát počet stupňů volnosti g aby bylo možné aplikovat test chí kvadrát.
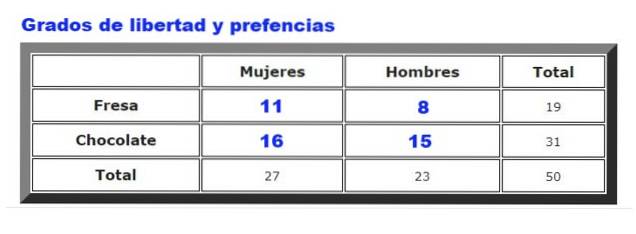
Jako příklad budou analyzovány údaje shromážděné o preferencích čokoládové nebo jahodové zmrzliny u mužů a žen v určitém zmrzlinovém salónu. Četnost, s jakou si muži a ženy volí jahody nebo čokoládu, je shrnuta na obrázku 2.
Nejprve se vypočítá tabulka očekávaných frekvencí, která se připraví vynásobením celkem řádků pro něj celkem sloupců, děleno celková data. Výsledek ukazuje následující obrázek:

Poté přistoupíme k výpočtu čtverce Chi (z údajů) pomocí následujícího vzorce:
χdva = ∑ (F.nebo - Fa)dva / F.a
Kde Fnebo jsou pozorované frekvence (obrázek 2) a Fa jsou očekávané frekvence (obrázek 3). Součet jde přes všechny řádky a sloupce, které v našem příkladu obsahují čtyři výrazy.
Po provedení operací získáte:
χdva = 0,2043.
Nyní je nutné porovnat s teoretickým chí kvadrátem, který závisí na počet stupňů volnosti g.
V našem případě je toto číslo určeno následovně:
g = (# řádky - 1) (# sloupce - 1) = (2 - 1) (2 - 1) = 1 * 1 = 1.
Ukazuje se, že počet stupňů volnosti g v tomto příkladu je 1.
Pokud chcete zkontrolovat nebo odmítnout nulovou hypotézu (H0: neexistuje korelace mezi CHUŤEM a POHLAVÍ) s hladinou významnosti 1%, teoretická hodnota chí-kvadrát se počítá se stupněm volnosti g = 1.
Hledá se hodnota, která činí akumulovanou frekvenci (1 - 0,01) = 0,99, tj. 99%. Tato hodnota (kterou lze získat z tabulek) je 6,636.
Protože teoretická Chi překračuje vypočítanou, ověřuje se nulová hypotéza.
To znamená se shromážděnými údaji, Není pozorováno vztah mezi proměnnými CHUŤ a ROD.



Zatím žádné komentáře