The míry variability, Také se nazývají míry disperze, jsou to statistické ukazatele, které označují, jak blízko nebo daleko jsou data od svého aritmetického průměru. Pokud jsou data blízko průměru, distribuce se koncentruje, a pokud jsou daleko, pak se jedná o řídké rozdělení..
Existuje mnoho měr variability, mezi nejznámější patří:
Tato opatření doplňují opatření centrální tendence a jsou nezbytná k pochopení distribuce získaných dat a extrakci z nich co nejvíce informací..
Rozsah nebo rozpětí měří šířku datové sady. K určení jeho hodnoty je rozdíl mezi daty s nejvyšší hodnotou xmax a ten s nejnižší hodnotou xmin:
R = xmax - Xmin
Pokud data nejsou volná, ale seskupená podle intervalu, pak se rozsah vypočítá z rozdílu mezi horní hranicí posledního intervalu a spodní hranicí prvního intervalu.
Pokud je rozsah malou hodnotou, znamená to, že jsou všechna data poměrně blízko u sebe, ale velký rozsah naznačuje, že existuje velká variabilita. Je zřejmé, že kromě horní a dolní meze dat rozsah nezohledňuje hodnoty mezi nimi, proto se nedoporučuje jej používat, když je počet dat velký.
Jedná se však o okamžité opatření k výpočtu a má stejné jednotky dat, takže je snadné jej interpretovat.
Níže je uveden seznam gólů vstřelených během víkendu ve fotbalových ligách devíti zemí:
40, 32, 35, 36, 37, 31, 37, 29, 39
Toto je neseskupená datová sada. Abychom našli rozsah, pokračujeme v jejich seřazení od nejnižší po nejvyšší:
29, 31, 32, 35, 36, 37, 37, 39, 40
Data s nejvyšší hodnotou jsou 40 cílů a ta s nejnižší hodnotou je 29 cílů, proto je rozsah:
R = 40−29 = 11 gólů.
Lze předpokládat, že rozsah je malý ve srovnání s údaji o minimální hodnotě, což je 29 cílů, takže lze předpokládat, že data nemají velkou variabilitu.
Tato míra variability se vypočítá z průměru absolutních hodnot odchylek vzhledem k průměru.. Označení střední odchylky jako DM, U neseskupených údajů se střední odchylka vypočítá pomocí následujícího vzorce:
Kde n je počet dostupných dat, xi představuje každé údaje a x̄ je průměr, který je určen sečtením všech údajů a vydělením n:
Střední odchylka umožňuje v průměru zjistit, v kolika jednotkách se data odchylují od aritmetického průměru, a má tu výhodu, že mají stejné jednotky jako data, se kterými pracujeme.
Na základě údajů z příkladu rozsahu je počet vstřelených gólů:
40, 32, 35, 36, 37, 31, 37, 29, 39
Pokud chcete najít střední odchylku DM Z těchto údajů je nutné nejprve vypočítat aritmetický průměr x̄:

Nyní, když je známa hodnota x̄, pokračujeme v hledání střední odchylky DM:
= 2,99 ≈ 3 góly
Lze tedy konstatovat, že v průměru jsou data vzdálena přibližně od průměru 3, což je 35 cílů, a jak již bylo uvedeno, jedná se o mnohem přesnější měřítko, než je rozsah..
Střední odchylka je mnohem jemnějším měřítkem variability než rozsah, ale protože se počítá z absolutní hodnoty rozdílů mezi každým datem a střední hodnotou, nenabízí větší univerzálnost z algebraického hlediska..
Z tohoto důvodu se dává přednost rozptylu, který odpovídá průměru kvadratického rozdílu jednotlivých dat se střední hodnotou a vypočítá se pomocí vzorce:
V tomto výrazu sdva označuje rozptyl a jako vždy xi představuje každé z dat, x̄ je průměr an je celkový údaj.
Při práci se vzorkem místo s populací je výhodné vypočítat rozptyl takto:
V každém případě je rozptyl charakterizován tím, že je vždy kladnou veličinou, ale protože se jedná o průměr kvadratických rozdílů, je důležité si uvědomit, že nemá stejné jednotky jako jednotky údajů..
Pro výpočet rozptylu dat v příkladech rozsahu a střední odchylky přistoupíme k nahrazení odpovídajících hodnot a provedeme indikovaný součet. V tomto případě se rozhodneme vydělit n-1:

= 13,86
Rozptyl nemá stejnou jednotku jako sledovaná proměnná, například pokud jsou data uvedena v metrech, výsledkem rozptylu jsou metry čtvereční. Nebo v příkladu cílů by to bylo v cílech na druhou, což nedává smysl.
Proto je definována standardní odchylka, také nazývaná typická odchylka, jako druhá odmocnina rozptylu:
s = √sdva
Tímto způsobem se získá míra variability dat ve stejných jednotkách jako tyto, a čím nižší je hodnota s, tím více jsou data seskupena kolem průměru..
Jak rozptyl, tak směrodatná odchylka jsou měřítkem variability, která se má zvolit, když je aritmetický průměr měřítkem centrální tendence, která nejlépe vystihuje chování dat..
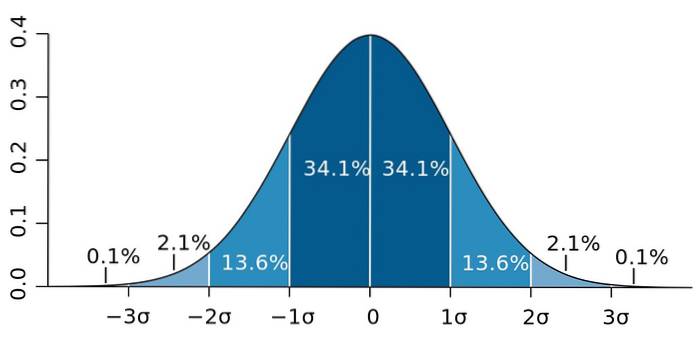
A je to tak, že směrodatná odchylka má důležitou vlastnost, známou jako Čebyševova věta: minimálně 75% pozorování je v intervalu definovaném X ± 2 s. Jinými slovy, 75% dat je maximálně 2 s od průměru..
Podobně nejméně 89% hodnot je ve vzdálenosti 3 s od průměru, což je procento, které lze rozšířit, pokud je k dispozici spousta dat a dodržují normální rozdělení..
Obrázek 2. - Pokud data sledují normální rozdělení, 95,4 z nich je ve dvou standardních odchylkách na obou stranách průměru. Zdroj: Wikimedia Commons.
Směrodatná odchylka údajů uvedených v předchozích příkladech je:
s = √sdva = √ 13,86 = 3,7 ≈ 4 góly



Zatím žádné komentáře