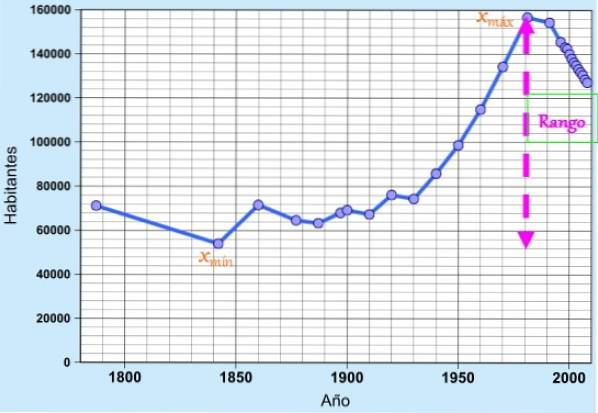
The hodnost, vzdálenost nebo amplituda ve statistikách je rozdíl (odčítání) mezi maximální hodnotou a minimální hodnotou souboru dat ze vzorku nebo populace. Pokud je rozsah reprezentován písmenem R a data symbolem X, vzorec pro rozsah je jednoduše:
R = xmax - Xmin
Kde xmax je maximální hodnota dat a xmin je minimum.
Koncept je velmi užitečný jako jednoduchá míra rozptylu k rychlému ohodnocení variability dat, protože označuje prodloužení nebo délku intervalu, kde se nacházejí..
Předpokládejme například, že se měří výška skupiny 25 mužských studentů prvního ročníku na univerzitě. Nejvyšší student ve skupině je 1,93 ma nejkratší 1,67 m. Jedná se o extrémní hodnoty ukázkových dat, proto je jejich cesta:
R = 1,93 - 1,67 m = 0,26 m nebo 26 cm.
Výška studentů v této skupině je rozdělena do tohoto rozsahu.
Rejstřík článků
Rozsah je, jak jsme již řekli, měřítkem šíření dat. Malý rozsah naznačuje, že data jsou víceméně blízká a že je málo rozšířená. Na druhou stranu větší rozsah naznačuje, že data jsou více rozptýlena..
Výhody výpočtu rozsahu jsou zřejmé: jeho vyhledání je velmi jednoduché a rychlé, protože jde o jednoduchý rozdíl.
Má také stejné jednotky jako data, se kterými pracuje, a koncept je pro každého pozorovatele velmi snadno interpretovatelný..
Na příkladu výšky studentů inženýrství, kdyby byl dosah 5 cm, řekli bychom, že jsou všichni studenti přibližně stejné velikosti. Ale s rozsahem 26 cm okamžitě předpokládáme, že ve vzorku jsou studenti všech středních výšek. Je tento předpoklad vždy správný?
Pokud se podíváme pozorně, může se stát, že v našem vzorku 25 studentů strojírenství měří pouze jeden z nich 1,93 a zbývajících 24 má výšky blízké 1,67 m.
A přesto rozsah zůstává stejný, i když je zcela možné opak: že výška většiny je kolem 1,90 ma pouze jedna je 1,67 m.
V obou případech je distribuce dat zcela odlišná.
Nevýhody rozsahu jako měřítka rozptylu jsou, protože používá pouze extrémní hodnoty a ignoruje všechny ostatní. Protože většina informací je ztracena, nemáte tušení, jak jsou distribuována vzorová data.
Další důležitou charakteristikou je, že rozsah vzorku se nikdy nesníží. Pokud přidáme další informace, to znamená, vezmeme v úvahu více dat, rozsah se zvětší nebo zůstane stejný.
A v každém případě je to užitečné pouze při práci s malými vzorky, jeho jediné použití jako měřítko disperze ve velkých vzorcích se nedoporučuje..
Co musíte udělat, je doplnit výpočet dalších disperzních opatření, která berou v úvahu informace poskytnuté z celkových dat: trasa mezikvartilní, rozptyl, směrodatná odchylka a variační koeficient.
Uvědomili jsme si, že slabinou rozsahu jako míry rozptylu je to, že využívá pouze extrémní hodnoty distribuce dat, ostatní vynechává..
Aby se zabránilo těmto nepříjemnostem, kvartily: tři hodnoty známé jako měření polohy.
Distribuují neseskupená data do čtyř částí (další široce používané míry polohy jsou decilů a percentily). Jsou to jeho vlastnosti:
-První kvartil Q1 je hodnota dat taková, že 25% všech z nich je menší než Q1.
-Druhý kvartil Qdva je medián distribuce, což znamená, že polovina (50%) dat je menší než tato hodnota.
-Nakonec třetí kvartil Q3 poukazuje na to, že 75% dat je méně než Q3.
Potom je mezikvartilový rozsah nebo mezikvartilní rozsah definován jako rozdíl mezi třetím kvartilem Q3 a první kvartil Q1 údajů:
Mezikvartilní rozsah = RQ = Q3 - Q1
Tímto způsobem je hodnota rozsahu R.Q není to tak ovlivněno extrémními hodnotami. Z tohoto důvodu je vhodné jej použít při práci se zkosenými distribucemi, jako jsou výše popsané velmi vysoké nebo velmi krátké studenty..
Existuje několik způsobů, jak je vypočítat, zde jeden navrhneme, ale v každém případě je nutné znát číslo objednávky „Nnebo”, Což je místo, které příslušný kvartil zaujímá v distribuci.
To znamená, pokud je to například termín, který odpovídá Q1 je druhý, třetí nebo čtvrtý atd. distribuce.
Nnebo (Otázka1) = (N + 1) / 4
Nnebo (Otázkadva) = (N + 1) / 2
Nnebo (Otázka3) = 3 (N + 1) / 4
Kde N je počet dat.
Medián je hodnota, která je přímo uprostřed distribuce. Pokud je počet dat lichý, není problém je najít, ale pokud je sudý, pak se obě centrální hodnoty zprůměrují na jednu.
Po výpočtu čísla objednávky se použije jedno z těchto tří pravidel:
-Pokud nemá desetinná místa, budou prohledána data uvedená v distribuci a bude to prohledávaný kvartil.
-Když je číslo objednávky na půli cesty mezi dvěma, pak se data označená celočíselnou částí zprůměrují s následujícími daty a výsledkem je odpovídající kvartil.
-V každém jiném případě se zaokrouhlí na nejbližší celé číslo, což bude poloha kvartilu.
Na stupnici od 0 do 20 skupina 16 studentů matematiky I získala na průběžné zkoušce následující body (body):
16, 10, 12, 8, 9, 15, 18, 20, 9, 11, 1, 13, 17, 9, 10, 14
Nalézt:
a) Rozsah nebo rozsah dat.
b) Hodnoty kvartilů Q1 a Q3
c) Mezikvartilní rozsah.

První věcí, kterou je třeba najít, je seřadit data ve vzestupném nebo sestupném pořadí. Například v rostoucím pořadí máte:
1, 8, 9, 9, 9, 10, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20
Pomocí vzorce uvedeného na začátku: R = xmax - Xmin
R = 20 - 1 bod = 19 bodů.
Podle výsledku mají tyto kvalifikace velký rozptyl.
N = 16
Nnebo (Otázka1) = (N + 1) / 4 = (16 + 1) / 4 = 17/4 = 4,25
Je to číslo s desetinnými místy, jehož celočíselná část je 4. Pak přejdeme k distribuci, hledáme data, která zaujímají čtvrté místo a jejich hodnota je zprůměrována s hodnotou páté pozice. Jelikož jsou oba 9, průměr je také 9 a tak:
Q1 = 9
Nyní postup opakujeme, abychom našli Q3:
Nnebo (Otázka3) = 3 (N + 1) / 4 = 3 (16 +1) / 4 = 12,75
Opět je to desetinné číslo, ale protože to není v polovině cesty, zaokrouhlí se na 13. Kvartil, který hledáme, zaujímá třináctou pozici a je:
Q3 = 16
RQ = Q3 - Q1 = 16 - 9 = 7 bodů.
Což, jak vidíme, je mnohem menší než rozsah dat vypočítaný v části a), protože minimální skóre bylo 1 bod, což je hodnota mnohem dále od ostatních..


Zatím žádné komentáře