
The koeficient stanovení je číslo mezi 0 a 1, které představuje zlomek bodů (X, Y), které sledují regresní linii přizpůsobení sady dat se dvěma proměnnými.
Je také známý jako dobrota fit a je označen Rdva. Pro jeho výpočet se vezme kvocient mezi rozptylem dat Ŷi odhadovaným regresním modelem a rozptylem dat Yi odpovídající každému Xi dat..
Rdva = S / Sy

Pokud je 100% dat na řádku regresní funkce, pak bude koeficient stanovení 1.
Naopak, pokud pro soubor dat a určitou funkci úpravy je koeficient Rdva Ukázalo se, že se rovná 0,5, pak lze říci, že fit je 50% uspokojivý nebo dobrý.
Podobně, když regresní model vrací hodnoty R.dva nižší než 0,5, znamená to, že zvolená funkce nastavení se nepřizpůsobuje uspokojivě datům, proto je nutné hledat jinou funkci nastavení.
A když kovariance nebo korelační koeficient má tendenci k nule, pak proměnné X a Y v datech nesouvisí, a proto Rdva bude mít také tendenci k nule.
Rejstřík článků
V předchozí části bylo řečeno, že koeficient stanovení se vypočítá nalezením kvocientu mezi odchylkami:
-Odhadováno regresní funkcí proměnné Y
-Proměnná Yi odpovídající každé z proměnných Xi N datových párů.
Vyjádřeno matematicky, vypadá to takto:
Rdva = S / Sy
Z tohoto vzorce vyplývá, že Rdva představuje podíl rozptylu vysvětlený regresním modelem. Alternativně lze vypočítat R.dva pomocí následujícího vzorce, zcela ekvivalentního předchozímu:
Rdva = 1 - (Sε / Sy)
Kde Sε představuje rozptyl reziduí εi = Ŷi - Yi, zatímco Sy je rozptyl sady hodnot Yi dat. K určení Ŷi se použije regresní funkce, což znamená potvrdit, že Ŷi = f (Xi).
Rozptyl datové sady Yi s i od 1 do N se vypočítá takto:
Sy = [Σ (Yi -
A pak postupujte podobným způsobem pro Sŷ nebo pro Sε.
Za účelem zobrazení podrobností o tom, jak je výpočet koeficient stanovení vezmeme následující sadu čtyř párů dat:
(X, Y): (1, 1); (2.3); (3, 6) a (4, 7).
Pro tento soubor dat je navrženo lineární regrese, které se získá metodou nejmenších čtverců:
f (x) = 2,1 x - 1
Použitím této funkce nastavení se získají momenty:
(X, Ŷ): (1, 1,1); (2, 3,2); (3, 5,3) a (4, 7,4).
Poté vypočítáme aritmetický průměr pro X a Y:
Variance Sy
Sy = [(1 - 4,25)dva + (3 - 4,25)dva + (6 - 4,25)dva +….…. (7 - 4,25)dva] / (4-1) =
= [(-3,25)dva+ (-1,25)dva + (1,75)dva + (2,75)dva) / (3)] = 7583
Variance Sŷ
Sŷ = [(1,1 - 4,25)dva + (3,2 - 4,25)dva + (5,3 - 4,25)dva +….…. (7,4 - 4,25)dva] / (4-1) =
= [(-3,25)dva + (-1,25)dva + (1,75)dva + (2,75)dva) / (3)] = 7,35
Koeficient stanovení Rdva
Rdva = S / Sy = 7,35 / 7,58 = 0,97
Koeficient stanovení pro ilustrativní případ uvažovaný v předchozím segmentu se ukázal být 0,98. Jinými slovy, lineární nastavení pomocí funkce:
f (x) = 2,1x - 1
Je 98% spolehlivé při vysvětlování dat, s nimiž bylo získáno pomocí metody nejmenších čtverců..
Kromě koeficientu determinace existuje lineární korelační koeficient nebo také známý jako Pearsonův koeficient. Tento koeficient označený jako r, se vypočítá z následujícího vztahu:
r = Sxy / (Sx Sy)
Zde čitatel představuje kovarianci mezi proměnnými X a Y, zatímco jmenovatel je součinem směrodatné odchylky pro proměnnou X a směrodatné odchylky pro proměnnou Y.
Pearsonův koeficient může nabývat hodnot mezi -1 a +1. Když má tento koeficient sklon +1, existuje přímá lineární korelace mezi X a Y. Pokud má místo toho sklon -1, existuje lineární korelace, ale když X stoupá, Y klesá. Nakonec je blízko 0, neexistuje žádná korelace mezi těmito dvěma proměnnými.
Je třeba poznamenat, že koeficient stanovení se shoduje s druhou mocninou Pearsonova koeficientu, pouze když byl první vypočítán na základě lineárního uložení, ale tato rovnost není platná pro ostatní nelineární tvarovky..
Skupina studentů středních škol se rozhodla stanovit empirický zákon na dobu kyvadla v závislosti na jeho délce. K dosažení tohoto cíle provádějí řadu měření, při nichž měří čas kmitání kyvadla pro různé délky a získávají následující hodnoty:
| Délka (m) | Období |
|---|---|
| 0,1 | 0,6 |
| 0,4 | 1.31 |
| 0,7 | 1,78 |
| 1 | 1,93 |
| 1.3 | 2.19 |
| 1.6 | 2.66 |
| 1.9 | 2.77 |
| 3 | 3.62 |
Je požadováno provést bodový graf dat a provést lineární přizpůsobení pomocí regrese. Ukažte také regresní rovnici a její koeficient stanovení.
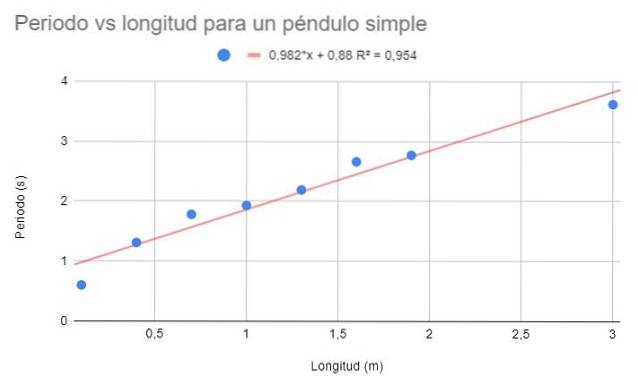
Lze pozorovat poměrně vysoký koeficient stanovení (95%), takže lze předpokládat, že lineární uložení je optimální. Pokud se však na body díváme společně, ukazuje se, že mají tendenci se zakřivovat směrem dolů. Tento detail není uvažován v lineárním modelu.
Pro stejná data v příkladu 1 vytvořte bodový graf dat. Při této příležitosti je na rozdíl od příkladu 1 požadována regresní úprava pomocí potenciální funkce.
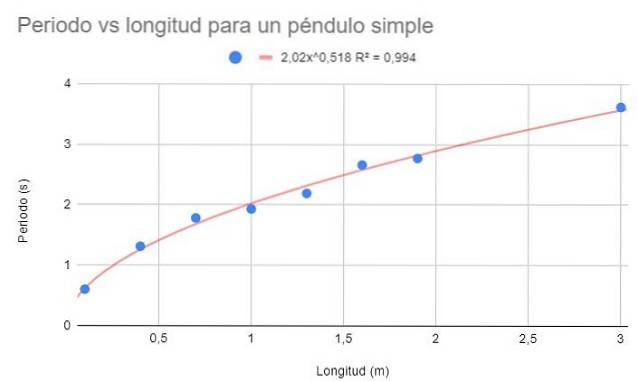
Uveďte také fitovací funkci a její koeficient stanovení Rdva.
Potenciální funkce má tvar f (x) = AxB, kde A a B jsou konstanty, které jsou určeny metodou nejmenších čtverců.
Předchozí obrázek ukazuje potenciální funkci a její parametry, jakož i koeficient stanovení s velmi vysokou hodnotou 99%. Všimněte si, že data sledují zakřivení trendové čáry.
Pomocí stejných dat z příkladu 1 a příkladu 2 proveďte polynomiální přizpůsobení druhého stupně. Zobrazit graf, polynom fit a koeficient determinace Rdva korespondent.
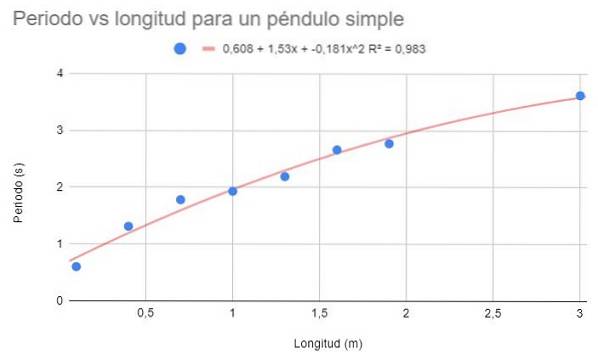
S polynomickým přizpůsobením druhého stupně můžete vidět trendovou čáru, která dobře zapadá do zakřivení dat. Koeficient determinace je také nad lineárním uložením a pod potenciálním uložením..
Ze tří ukázaných fitů je potenciálním fitem ten s nejvyšším koeficientem determinace (příklad 2).
Potenciální fit se shoduje s fyzikální teorií kyvadla, která, jak je známo, stanoví, že doba kyvadla je úměrná druhé odmocnině jeho délky, konstanta proporcionality je 2π / √g, kde g je zrychlení gravitace.
Tento typ přizpůsobení potenciálu má nejen nejvyšší koeficient determinace, ale exponent a konstanta proporcionality odpovídají fyzickému modelu..
-Regresní přizpůsobení určuje parametry funkce, která má vysvětlit data pomocí metody nejmenších čtverců. Tato metoda spočívá v minimalizaci součtu čtvercového rozdílu mezi hodnotou Y úpravy a hodnotou Yi dat pro hodnoty Xi dat. To určuje parametry funkce nastavení.
-Jak jsme viděli, nejběžnější funkcí úpravy je přímka, ale není to jediná, protože úpravy mohou být také polynomické, potenciální, exponenciální, logaritmické a další..
-V každém případě závisí koeficient determinace na datech a typu lícování a je údajem o dobré povaze aplikovaného lícování..
-Nakonec koeficient stanovení udává procento celkové variability mezi hodnotou Y dat vzhledem k hodnotě of fit pro dané X.


Zatím žádné komentáře