The neseskupená data jsou ty, které získané studiem ještě nejsou organizovány podle tříd. Pokud se jedná o zvládnutelný počet dat, obvykle 20 nebo méně, a existuje jen málo různých dat, lze s nimi zacházet jako s neseskupenými a z nich získanými hodnotnými informacemi.
Neseskupené údaje pocházejí z průzkumu nebo studie provedené za účelem jejich získání, a proto postrádají zpracování. Podívejme se na několik příkladů:

-Výsledky IQ testu na 20 náhodných studentech z univerzity. Získané údaje byly následující:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112,106
-Věk 20 zaměstnanců určité oblíbené kavárny:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
-Průměrná známka 10 studentů ve třídě matematiky:
3,2; 3,1; 2,4; 4,0; 3,5; 3,0; 3,5; 3,8; 4,2; 4.9
Rejstřík článků
Existují tři důležité vlastnosti, které charakterizují sadu statistických dat, ať už jsou nebo nejsou seskupeny, které jsou:
-Pozice, což je tendence dat shlukovat se kolem určitých hodnot.
-Rozptyl, údaj o tom, jak rozptýleny nebo rozptýleny jsou data kolem dané hodnoty.
-Tvar, Odkazuje na způsob, jakým jsou data distribuována, což se ocení, když je sestaven jejich graf. K dispozici jsou velmi symetrické křivky a také zkosené, buď nalevo, nebo napravo od určité centrální hodnoty.
Pro každou z těchto vlastností existuje řada opatření, která je popisují. Po získání nám poskytnou přehled o chování dat:
-Nejpoužívanějšími pozičními měřítky jsou aritmetický průměr nebo jednoduše průměr, medián a režim.
-Rozsah, rozptyl a směrodatná odchylka se často používají v disperzi, ale nejsou jediným měřítkem disperze..
-A abychom zjistili tvar, jsou průměr a medián porovnány pomocí zkreslení, jak brzy uvidíte.
-Aritmetický průměr, také známý jako průměr a označený jako X, se počítá takto:
X = (x1 + Xdva + X3 +… Xn) / n
Kde x1, Xdva,…. Xn, jsou data an je jejich součet. V součtové notaci máme:
-Medián je hodnota, která se objeví uprostřed uspořádané sekvence dat, takže k jejímu získání je nutné nejprve objednat data.
Pokud je počet pozorování lichý, není problém najít střed sady, ale pokud máme sudý počet dat, jsou prohledána a zprůměrována dvě centrální data.
-Móda je nejběžnější hodnota pozorovaná v souboru dat. Ne vždy existuje, protože je možné, že se žádná hodnota neopakuje častěji než jiná. Mohou existovat také dvě data se stejnou frekvencí, v takovém případě mluvíme o bimodálním rozdělení.
Na rozdíl od předchozích dvou opatření lze režim použít s kvalitativními údaji.
Podívejme se, jak se tyto míry polohy počítají na příkladu:
Předpokládejme, že chceme určit aritmetický průměr, medián a režim v příkladu navrženém na začátku: věk 20 zaměstnanců kavárny:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
The polovina vypočítá se jednoduše sečtením všech hodnot a vydělením n = 20, což je celkový počet dat. Takto:
X = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22,3 let.
Chcete-li najít medián nejprve musíte datovou sadu seřadit:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
Jelikož se jedná o sudý počet dat, jsou převzata a zprůměrována dvě centrální data zvýrazněná tučně. Protože je jim 22, střední hodnota je 22 let.
Nakonec móda Jedná se o data, která se nejvíce opakují, nebo ta, jejichž frekvence je větší, což je 22 let.
Rozsah je jednoduše rozdíl mezi největší a nejmenší z dat a umožňuje vám rychle ocenit variabilitu dat. Ale kromě toho existují další opatření k rozptylu, která nabízejí více informací o distribuci dat..
Rozptyl je označen jako s a je vypočítán výrazem:
Abychom správně interpretovali výsledky, směrodatná odchylka je definována jako druhá odmocnina rozptylu, nebo také kvazi-standardní odchylka, která je druhou odmocninou kvazi-rozptylu:
Jedná se o srovnání mezi průměrem X a mediánem Med:
-Pokud Med = střední X: data jsou symetrická.
-When X> Med: skew to the right.
-A pokud X < Med: los datos sesgan hacia la izquierda.
Najděte průměr, medián, režim, rozsah, rozptyl, směrodatnou odchylku a zkreslení pro výsledky IQ testu provedeného u 20 studentů z univerzity:
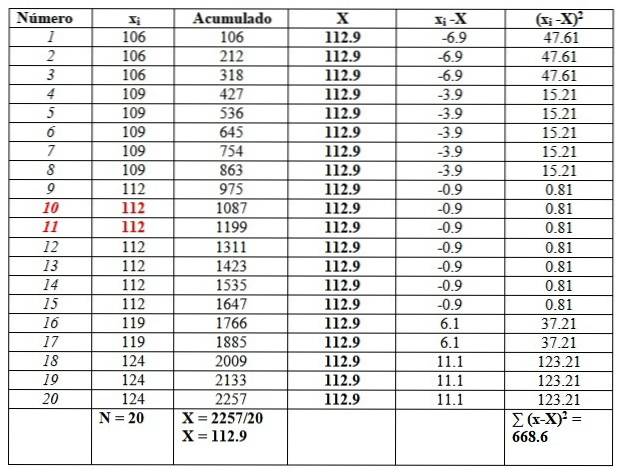
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
Údaje si objednáme, protože bude nutné najít medián.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 112, 112, 119, 119, 124, 124, 124
Abychom výpočty usnadnili, uvedeme je do tabulky následujícím způsobem. Druhý sloupec s názvem „Akumulované“ je součtem odpovídajících dat plus předchozí..
Tento sloupec pomůže snadno najít průměr vydělením posledního nashromážděného celkovým počtem dat, jak je vidět na konci sloupce Akumulované:
X = 112,9
Medián je průměr červeně zvýrazněných centrálních dat: číslo 10 a číslo 11. Jelikož jsou stejné, je medián 112.
Nakonec je režim hodnota, která se nejvíce opakuje a je 112 se 7 opakováními..
Pokud jde o míry disperze, rozsah je:
124-106 = 18.
Rozptyl se získá vydělením konečného výsledku v pravém sloupci n:
s = 668,6 / 20 = 33,42
V tomto případě je směrodatná odchylka druhá odmocnina rozptylu: √ 33,42 = 5,8.
Na druhou stranu jsou hodnoty kvazi-variance a kvazi standardní odchylky:
sC= 668,6 / 19 = 35,2
Kvazi-standardní odchylka = √35,2 = 5,9
Nakonec je zkreslení mírně napravo, protože průměr 112,9 je větší než medián 112.



Zatím žádné komentáře