The hypergeometrická distribuce je diskrétní statistická funkce, vhodná pro výpočet pravděpodobnosti v randomizovaných experimentech se dvěma možnými výsledky. Podmínkou, kterou je nutné použít, je, že se jedná o malé populace, ve kterých nejsou extrakce nahrazeny a pravděpodobnosti nejsou konstantní..
Když je tedy zvolen prvek populace, aby poznal výsledek (pravdivý nebo nepravdivý) určité charakteristiky, nelze tentýž prvek znovu vybrat..

Jistě je tedy pravděpodobnější, že další vybraný prvek získá skutečný výsledek, pokud měl předchozí prvek negativní výsledek. To znamená, že pravděpodobnost se liší, když jsou prvky extrahovány ze vzorku..
Hlavní aplikace hypergeometrické distribuce jsou: kontrola kvality v procesech s malým počtem obyvatel a výpočet pravděpodobností ve hazardních hrách.
Pokud jde o matematickou funkci, která definuje hypergeometrické rozdělení, skládá se ze tří parametrů, kterými jsou:
- Počet prvků populace (N)
- Velikost vzorku (m)
- Počet událostí v celé populaci s příznivým (nebo nepříznivým) výsledkem studované charakteristiky (n).
Rejstřík článků
Pravděpodobnost dává vzorec pro hypergeometrické rozdělení P o čem X nastanou příznivé případy určité charakteristiky. Způsob, jak to matematicky napsat na základě kombinačních čísel, je:
Ve výše uvedeném výrazu N, n Y m jsou parametry a X samotná proměnná.
-Celkový počet obyvatel je N.
-Počet pozitivních výsledků určité binární charakteristiky vzhledem k celkové populaci je n.
-Množství ukázkových položek je m.
V tomto případě, X je náhodná proměnná, která má hodnotu X Y P (x) označuje pravděpodobnost výskytu X příznivé případy studované charakteristiky.
Další statistické proměnné pro hypergeometrické rozdělení jsou:
- Polovina μ = m * n / N
- Rozptyl σ ^ 2 = m * (n / N) * (1-n / N) * (N-m) / (N-1)
- Typická odchylka σ což je druhá odmocnina rozptylu.
Abychom dospěli k modelu hypergeometrického rozdělení, vycházíme z pravděpodobnosti získání X příznivé případy ve velikosti vzorku m. Uvedený vzorek obsahuje prvky, které odpovídají studované vlastnosti, a prvky, které tomu tak není.
Pamatuj si to n představuje počet příznivých případů v celkové populaci N elementy. Pravděpodobnost by se pak počítala takto:
P (x) = (# způsobů, jak získat x # neúspěšných způsobů) / (celkem # způsobů výběru)
Vyjádříme-li výše uvedené ve formě kombinatorických čísel, dospějeme k následujícímu modelu rozdělení pravděpodobnosti:
Jsou to následující:
- Vzorek musí být vždy malý, i když je populace velká.
- Prvky vzorku jsou extrahovány jeden po druhém, aniž by byly začleněny zpět do populace.
- Vlastnost, která má být studována, je binární, to znamená, že může mít pouze dvě hodnoty: 1 nebo 0, dobře určitý nebo falešný.
V každém kroku extrakce prvku se pravděpodobnost mění v závislosti na předchozích výsledcích.
Další vlastností hypergeometrického rozdělení je, že jej lze aproximovat binomickým rozdělením, označeným jako Bi, tak dlouho, jak populace N je velký a nejméně 10krát větší než vzorek m. V tomto případě by to vypadalo takto:
P (N, n, m; x) = Bi (m, n / N, x)
Použitelné, pokud je N velké a N> 10 m
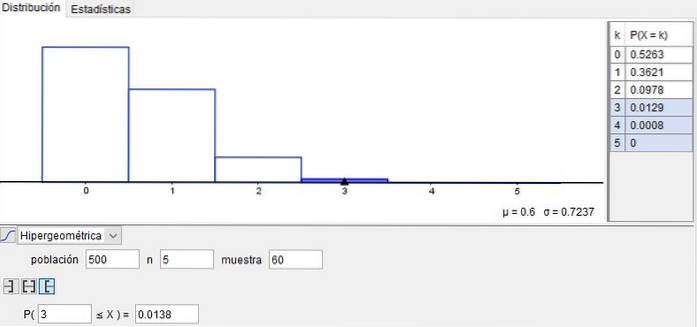
Předpokládejme, že stroj, který vyrábí šrouby, a souhrnná data naznačují, že 1% vychází s vadami. Pak v krabici N = 500 šroubů bude počet vadných:
n = 500 * 1/100 = 5
Předpokládejme, že z této krabice (tj. Z této populace) vezmeme vzorek šroubů m = 60.
Pravděpodobnost, že ve vzorku není vadný žádný šroub (x = 0), je 52,63%. Tohoto výsledku je dosaženo pomocí funkce hypergeometrické distribuce:
P (500, 5, 60, 0) = 0,5263
Pravděpodobnost, že x = 3 šrouby ve vzorku jsou vadné, je: P (500, 5, 60, 3) = 0,0129.
Na druhou stranu pravděpodobnost, že x = 4 šrouby ze šedesáti vzorků jsou vadné, je: P (500, 5, 60; 4) = 0,0008.
A konečně, pravděpodobnost, že x = 5 šroubů v tomto vzorku je vadných, je: P (500, 5, 60; 5) = 0.
Pokud však chcete vědět pravděpodobnost, že v tomto vzorku jsou více než 3 vadné šrouby, musíte získat kumulativní pravděpodobnost a přidat:
P (3) + P (4) + P (5) = 0,0129 + 0,0008 + 0 = 0,0137.
Tento příklad je znázorněn na obrázku 2, získaný použitím GeoGebra bezplatný software široce používaný ve školách, ústavech a univerzitách.
Španělský balíček má 40 karet, z nichž 10 má zlato a zbývajících 30 ne. Předpokládejme, že z tohoto balíčku bude náhodně vytaženo 7 karet, které nebudou znovu začleněny do balíčku.
Pokud X je počet zlatých přítomných na 7 vylosovaných kartách, pak je pravděpodobnost, že v losování 7 karet bude x zlatých, dána hypergeometrickým rozdělením P (40,10,7; x).
Podívejme se na to takto: k výpočtu pravděpodobnosti 4 zlatých v tahu 7 karet použijeme vzorec hypergeometrického rozdělení s následujícími hodnotami:

A výsledek je: 4,57% pravděpodobnost.
Pokud ale chcete znát pravděpodobnost získání více než 4 karet, musíte přidat:
P (4) + P (5) + P (6) + P (7) = 5,20%
Následující sada cvičení je určena k ilustraci a přizpůsobení konceptů, které byly představeny v tomto článku. Je důležité, aby se je čtenář pokusil vyřešit sám, než se podívá na řešení.
Továrna na kondomy zjistila, že z každých 1000 kondomů vyrobených určitým strojem je 5 vadných. Pro kontrolu kvality je náhodně odebráno 100 kondomů a šarže je odmítnuta, pokud je alespoň jeden vadný. Odpovědět:
a) Jaká je možnost, že hodně 100 bude vyřazeno?
b) Je toto kritérium kontroly kvality účinné??
V tomto případě se objeví velmi velká kombinatorická čísla. Výpočet je obtížný, pokud není k dispozici vhodný softwarový balíček.
Ale protože se jedná o velkou populaci a vzorek je desetkrát menší než celková populace, je možné použít aproximaci hypergeometrického rozdělení binomickým rozdělením:
P (1 000 5 100; x) = Bi (100, 5/1000, x) = Bi (100, 0,005, x) = C (100, x) * 0,005 ^ x (1-0,005) ^ (100-x)
Ve výše uvedeném výrazu C (100, x) je kombinatorické číslo. Pravděpodobnost, že bude více než jedna vadná, se vypočítá takto:
P (x> = 1) = 1 - Bi (0) = 1- 0,6058 = 0,3942
Je to vynikající aproximace, pokud se porovná s hodnotou získanou použitím hypergeometrického rozdělení: 0,4102
Lze říci, že s 40% pravděpodobností by měla být dávka 100 profylaktik zlikvidována, což není příliš efektivní..
Ale vzhledem k tomu, že v procesu kontroly kvality je to o něco méně náročné a dávku 100 bychom vyřadili, pouze pokud by existovaly dva nebo více defektů, pak by pravděpodobnost vyřazení dávky klesla na pouhých 8%..
Stroj na plastové zátky funguje tak, že z každých 10 kusů vyjde jeden zdeformovaný. Jak pravděpodobné je u vzorku 5 kusů, že je vadný pouze jeden kus?.
Počet obyvatel: N = 10
Počet n vad pro každé N: n = 1
Velikost vzorku: m = 5
P (10, 1, 5; 1) = C (1,1) * C (9,4) / C (10,5) = 1 * 126/252 = 0,5
Proto existuje 50% pravděpodobnost, že ve vzorku 5 vyjde tágo deformované.
Na setkání mladých maturantů je 7 dám a 6 pánů. Z dívek 4 studovaly humanitní vědy a 3 vědy. Ve skupině chlapců studovala 1 humanitní vědy a 5 věd. Vypočítejte následující:
a) Náhodný výběr tří dívek: jaká je pravděpodobnost, že všechny studují humanitní obory?.
b) Jsou-li náhodně vybráni tři účastníci schůzky přátel: Jaká je možnost, že tři z nich, bez ohledu na pohlaví, studují všechny tři vědu nebo humanitní také všechny tři?.
c) Nyní náhodně vyberte dva přátele a zavolejte X na náhodnou proměnnou „počet těch, kteří studují humanitní obory“. Mezi dvěma vybranými určete střední nebo očekávanou hodnotu X a rozptyl σ ^ 2.
Populace je celkový počet dívek: N = 7. Ti, kteří studují humanitní obory, jsou n = 4 z celkového počtu. Náhodný vzorek dívek bude m = 3.
V tomto případě je pravděpodobnost, že všichni tři jsou studenty humanitních oborů, dána hypergeometrickou funkcí:
P (N = 7, n = 4, m = 3, x = 3) = C (4, 3) C (3, 0) / C (7, 3) = 0,1143
Existuje tedy 11,4% pravděpodobnost, že tři náhodně vybrané dívky budou studovat humanitní obory..
Hodnoty, které se teď mají použít, jsou:
-Počet obyvatel: N = 14
-Množství, které studuje písmena, je: n = 6 a
-Velikost vzorku: m = 3.
-Počet přátel studujících humanitní vědy: x
Podle toho x = 3 znamená, že všechny tři studují humanitní obory, ale x = 0 znamená, že žádná studuje humanitní obory. Pravděpodobnost, že všechny tři studují totéž, je dána součtem:
P (14, 6, 3, x = 0) + P (14, 6, 3, x = 3) = 0,0560 + 0,1539 = 0,2099
Pak máme 21% pravděpodobnost, že tři náhodně vybraní účastníci schůzky budou studovat totéž.
Zde máme následující hodnoty:
N = 14 celková populace přátel, n = 6 celkový počet v populaci studující humanitní vědy, velikost vzorku je m = 2.
Naděje je:
E (x) = m * (n / N) = 2 * (6/14) = 0,8572
A rozptyl:
σ (x) ^ 2 = m * (n / N) * (1-n / N) * (Nm) / (N-1) = 2 * (6/14) * (1-6 / 14) * (14-2) / (14 -1) =
= 2 * (6/14) * (1-6 / 14) * (14-2) / (14-1) = 2 * (3/7) * (1-3 / 7) * (12) / (13 ) = 0,4521


Zatím žádné komentáře