The známka třídy, Také známý jako střed, je to hodnota, která je ve středu třídy, což představuje všechny hodnoty, které jsou v dané kategorii. V zásadě se značka třídy používá k výpočtu určitých parametrů, jako je aritmetický průměr nebo směrodatná odchylka..
Značka třídy je tedy středem jakéhokoli intervalu. Tato hodnota je také velmi užitečná k nalezení rozptylu sady dat již seskupených do tříd, což nám zase umožňuje pochopit, jak daleko od centra jsou tato konkrétní data umístěna.

Rejstřík článků
Abychom pochopili, co je značka třídy, je nezbytný koncept distribuce frekvence. Vzhledem k souboru dat je frekvenční distribuce tabulka, která rozděluje data do několika kategorií nazývaných třídy..
Uvedená tabulka ukazuje množství prvků, které patří do každé třídy; druhá je známá jako frekvence.
V této tabulce je obětována část informací, které získáváme z dat, protože místo individuální hodnoty každého prvku víme jen to, že patří do dané třídy.
Na druhou stranu získáme lepší porozumění datové sadě, protože tímto způsobem je snazší ocenit zavedené vzory, což usnadňuje manipulaci s uvedenými daty..
Abychom mohli rozdělit frekvenci, musíme nejprve určit počet tříd, které chceme absolvovat, a zvolit jejich limity tříd..
Volba počtu tříd, které je třeba absolvovat, by měla být pohodlná, s přihlédnutím k tomu, že malý počet tříd může skrýt informace o datech, která chceme studovat, a velmi velký může generovat příliš mnoho podrobností, které nejsou nutně užitečné.
Faktorů, které musíme vzít v úvahu při výběru, kolik tříd je třeba vzít, je několik, ale mezi těmito dvěma vynikají: první je vzít v úvahu, kolik dat musíme vzít v úvahu; druhým je vědět, jak velký je rozsah distribuce (tj. rozdíl mezi největším a nejmenším pozorováním).
Poté, co už máme třídy definované, pokračujeme v počítání, kolik dat v každé třídě existuje. Toto číslo se nazývá frekvence tříd a je označeno fi.
Jak jsme již dříve řekli, zjistíme, že rozdělení kmitočtů ztrácí informace, které pocházejí jednotlivě z každého údaje nebo pozorování. Z tohoto důvodu je hledána hodnota, která představuje celou třídu, do které patří; tato hodnota je značka třídy.
Značka třídy je základní hodnotou, kterou třída představuje. Získává se přidáním mezí intervalu a dělením této hodnoty dvěma. Mohli bychom to vyjádřit matematicky takto:
Xi= (Dolní limit + horní limit) / 2.
V tomto výrazu xi označuje známku i-té třídy.
Vzhledem k následující sadě dat uveďte reprezentativní rozdělení frekvence a získejte známku odpovídajících tříd.

Protože data s nejvyšší číselnou hodnotou je 391 a nejnižší je 221, máme rozsah 391 -221 = 170.
Vybereme 5 tříd, všechny se stejnou velikostí. Jedním ze způsobů, jak vybrat třídy, je následující:

Všimněte si, že každá data jsou ve třídě, jsou disjunktní a mají stejnou hodnotu. Dalším způsobem, jak si vybrat třídy, je považovat data za součást spojité proměnné, která by mohla dosáhnout jakékoli skutečné hodnoty. V tomto případě můžeme uvažovat o třídách formuláře:
205-245, 245-285, 285-325, 325-365, 365-405
Tento způsob seskupování dat však může představovat určité hraniční nejasnosti. Například v případě 245 vyvstává otázka: do které třídy patří, první nebo druhá?
Aby se předešlo této nejasnosti, je vytvořena konvence koncového bodu. Tímto způsobem bude první třídou interval (205 245], druhá (245 285) atd..

Jakmile jsou třídy definovány, přistoupíme k výpočtu frekvence a máme následující tabulku:
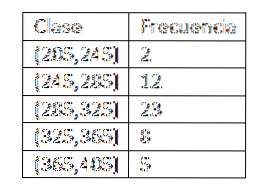
Po získání frekvenčního rozdělení dat pokračujeme v hledání třídních značek každého intervalu. Ve skutečnosti musíme:
X1= (205+ 245) / 2 = 225
Xdva= (245+ 285) / 2 = 265
X3= (285+ 325) / 2 = 305
X4= (325+ 365) / 2 = 345
X5= (365+ 405) / 2 = 385
Můžeme to vyjádřit následujícím grafem:
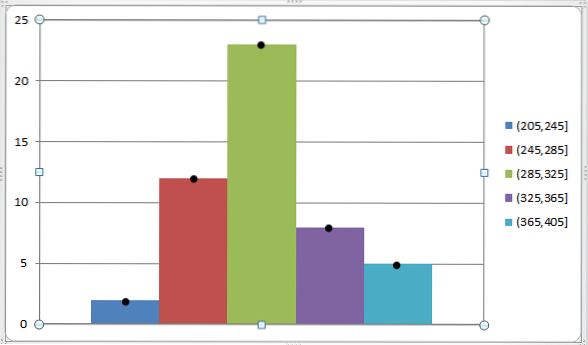
Jak již bylo zmíněno dříve, značka třídy je velmi funkční pro nalezení aritmetického průměru a rozptylu skupiny dat, která již byla seskupena do různých tříd..
Můžeme definovat aritmetický průměr jako součet pozorování získaných mezi velikostí vzorku. Z fyzikálního hlediska je jeho interpretace jako rovnovážný bod souboru dat.
Identifikace celé datové sady pomocí jediného čísla může být riskantní, takže je třeba vzít v úvahu také rozdíl mezi tímto bodem zlomu a skutečnými daty. Tyto hodnoty jsou známé jako odchylka od aritmetického průměru a pomocí nich se snažíme určit, jak moc se aritmetický průměr dat liší..
Nejběžnějším způsobem, jak tuto hodnotu zjistit, je rozptyl, což je průměr čtverců odchylek od aritmetického průměru.
Pro výpočet aritmetického průměru a rozptylu sady dat seskupených do třídy používáme následující vzorce:
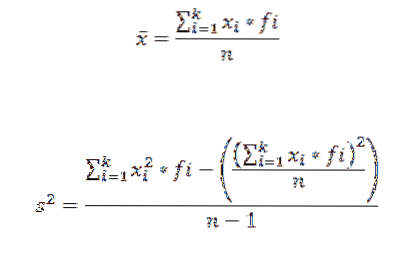
V těchto výrazech xi je značka i-té třídy, fi představuje odpovídající frekvenci ak počet tříd, ve kterých byla data seskupena.
Využíváme-li data uvedená v předchozím příkladu, máme možnost, že můžeme ještě trochu rozšířit data tabulky distribuce kmitočtů. Získáte následující:
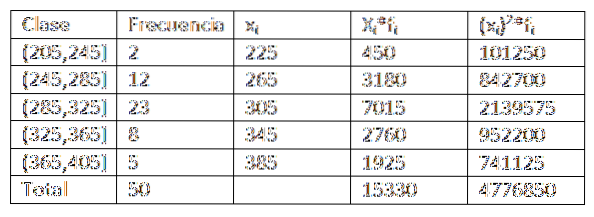
Poté, co nahradíme data ve vzorci, nám zbylo, že aritmetický průměr je:
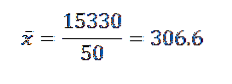
Jeho rozptyl a směrodatná odchylka jsou:
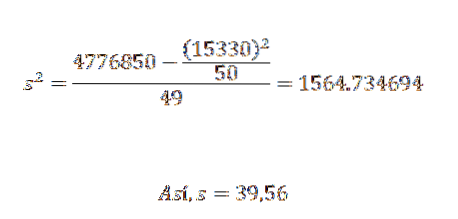
Z toho můžeme usoudit, že původní data mají aritmetický průměr 306,6 a standardní odchylku 39,56..



Zatím žádné komentáře