The vzorkování kvót Jedná se o nepravděpodobný způsob odběru dat ze vzorku přiřazením kvót vrstvami. Kvóty musí být úměrné zlomku, který tato vrstva představuje vzhledem k celkové populaci, a součet kvót se musí rovnat velikosti vzorku.
Výzkumník je ten, kdo rozhoduje o tom, jaké skupiny nebo vrstvy budou, například může rozdělit populaci na muže a ženy. Dalším příkladem vrstev jsou věkové skupiny, například od 18 do 25 let, od 26 do 40 let a od 40 let, které lze označit takto: mládež, dospělí a senioři.

Je velmi vhodné předem vědět, jaké procento z celkové populace představuje jednotlivé vrstvy. Poté je vybrána statisticky významná velikost vzorku a proporcionální kvóty jsou přiřazeny procentu každé vrstvy vzhledem k celkové populaci. Součet kvót na vrstvu se musí rovnat celkové velikosti vzorku.
Nakonec pokračujeme v získávání údajů o kvótách přiřazených každé vrstvě, přičemž vybereme první prvky, které kvótu dokončují.
Právě kvůli tomuto nenáhodnému způsobu výběru prvků je tato metoda vzorkování považována za nepravděpodobnou..
Rejstřík článků
Segmentujte celkovou populaci do vrstev nebo skupin s nějakou společnou charakteristikou. O této charakteristice dříve rozhodne statistický výzkumník provádějící studii..
Určete, jaké procento z celkové populace představuje každou z vrstev nebo skupin vybraných v předchozím kroku.
Odhadněte statisticky významnou velikost vzorku podle kritérií a metodik statistické vědy..
Vypočítejte počet prvků nebo kvót pro každou vrstvu tak, aby byly úměrné procentu, které každý z nich představuje vzhledem k celkové populaci a celkové velikosti vzorku..
Vezměte data prvků v každé vrstvě, dokud nedokončíte kvótu odpovídající každé vrstvě.
Předpokládejme, že chcete znát úroveň spokojenosti se službou metra ve městě. Předchozí studie na populaci 2 000 lidí určily, že 50% uživatelů je mladí mezi 16 a 21 lety je 40% Dospělí mezi 21 a 55 lety a pouze 10% uživatelů větší více než 55 let.
S využitím výsledků této studie je segmentována nebo stratifikována podle věku uživatelů:
-Mládež: padesátka%
-Dospělí: 40%
-Větší: 10%
Jelikož je rozpočet omezený, musí být studie použita na malém vzorku, ale statisticky významném. Je vybrán vzorek o velikosti 200, to znamená, že průzkum o míře spokojenosti bude aplikován celkem na 200 lidí.
Nyní je nutné určit kvótu nebo počet průzkumů pro každý segment nebo stratum, které musí být úměrné velikosti vzorku a procentuálnímu podílu na stratum..
Kvóta pro počet průzkumů na vrstvu je následující:
Mládež: 200 * 50% = 200 * (50/100) = 100 průzkumů
Dospělí: 200 * 40% = 200 * (40/100) = 80 průzkumů
Větší: 200 * 10% = 200 * (10/100) = 20 průzkumů
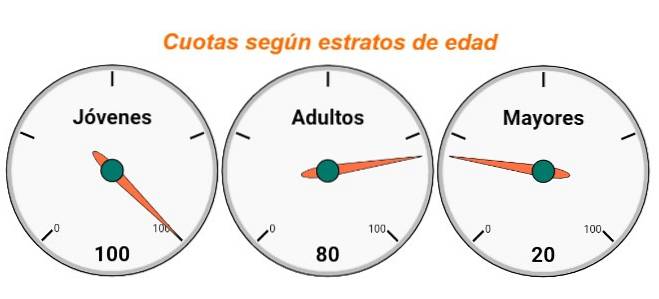
Součet kvót se musí rovnat velikosti vzorku, tj. Rovnat se celkovému počtu průzkumů, které budou použity. Poté jsou průzkumy předávány, dokud nejsou splněny kvóty pro jednotlivé vrstvy.
Je důležité si uvědomit, že tato metoda je mnohem lepší než provádět všechny průzkumy a předávat je prvním 200 lidem, kteří se objeví, protože podle předchozích údajů je velmi pravděpodobné, že ze studie bude vynechána menšinová vrstva.
Aby byla metoda použitelná, je pro vytvoření vrstev vyžadováno kritérium, které závisí na cíli studie..
Vzorkování kvót je vhodné, pokud chcete znát preference, rozdíly nebo charakteristiky podle sektorů k nasměrování konkrétních kampaní podle vrstvy nebo segmentu.
Jeho použití je také užitečné, když je z nějakého důvodu zajímavé znát charakteristiky nebo zájmy menšinových sektorů, nebo když je nechtějí vynechat ze studia.
Aby bylo možné použít, musí být známa váha nebo významnost každé vrstvy vzhledem k celkové populaci. Je velmi důležité, aby tyto znalosti byly spolehlivé, jinak budou získány chybné výsledky.
-Zkracuje dobu studia, protože kvóty na vrstvu jsou obvykle malé
-Zjednodušte analýzu dat.
-Minimalizuje náklady, protože studie se aplikuje na malé, ale dobře reprezentativní vzorky celkové populace.
-Jelikož jsou vrstvy definovány a priori, je možné, že určité sektory populace budou ze studie vynechány.
-Vytvořením omezeného počtu vrstev je možné, že se ve studii ztrácí detail.
-Odstraněním nebo začleněním některé vrstvy do jiné může dojít ke špatným závěrům ve studii.
-Znemožňuje odhadnout maximální chybu vzorkování.
Chcete udělat statistickou studii o úroveň úzkosti v populaci 2 000 lidí.
Výzkumník, který řídí výzkum, intuitivně usoudil, že rozdíly ve výsledcích musí být nalezeny v závislosti na věku a pohlaví. Z tohoto důvodu se rozhodl vytvořit tři věkové vrstvy označené takto: První_ věk, Second_Age Y Třetí_ věk. Pokud jde o segment sex jsou definovány dva obvyklé typy: mužský Y Ženský.
Definuje První_ věk, ten mezi 18 a 25 lety, Second_Age ten mezi 26 a 50 lety a konečně Třetí_ věk ten mezi 50 a 80 lety.
Při analýze údajů o celkové populaci je nutné:
45% populace patří k První_ věk.
40% je v Second_Age.
A konečně, pouze 15% studované populace patří k Třetí_ věk.
Za použití vhodné metodiky, která zde není podrobně uvedena, je statisticky významný vzorek 300 osob.
Dalším krokem pak bude nalezení odpovídajících kvót pro daný segment Stáří, což se děje následovně:
První_ věk: 300 * 45% = 300 * 45/100 = 135
Second_Age: 300 * 40% = 300 * 40/100 = 120
Třetí_ věk: 300 * 15% = 300 * 15/100 = 45
Ověřuje se, že součet kvót udává celkovou velikost vzorku.
Segment dosud nebyl zohledněn sex populace, v tomto segmentu již byly definovány dvě vrstvy: Ženský Y mužský. Opět musíme analyzovat údaje o celkové populaci, které poskytují následující informace:
-60% z celkové populace je pohlaví Ženský.
-Mezitím 40% studované populace patří k pohlaví mužský.
Je důležité si uvědomit, že předchozí procenta týkající se rozdělení populace podle pohlaví nezohledňují věk..
Vzhledem k tomu, že nejsou k dispozici žádné další informace, bude učiněn předpoklad, že tyto podíly z hlediska pohlaví jsou rovnoměrně rozloženy ve 3 vrstvách Stáří které byly pro tuto studii definovány. S těmito úvahami nyní pokračujeme ve stanovování kvót podle věku a pohlaví, což znamená, že nyní bude existovat 6 podvrstev:
S1 = První_věk a Žena: 135 * 60% = 135 * 60/100 = 81
S2 = První_Věk a Muž: 135 * 40% = 135 * 40/100 = 54
S3 = Second_Age a Female: 120 * 60% = 120 * 60/100 = 72
S4 = Second_Age a Male: 120 * 40% = 120 * 40/100 = 48
S5 = Třetí věk a Žena: 45 * 60% = 45 * 60/100 = 27
S6 = Třetí věk a muž: 45 * 40% = 45 * 40/100 = 18
Jakmile bude stanoveno šest (6) segmentů a jejich odpovídající kvóty, je připraveno 300 průzkumů, které budou použity podle již vypočítaných kvót..
Průzkumy budou použity následovně, bude provedeno 81 průzkumů a dotazováno je prvních 81 lidí, kteří jsou v tomto segmentu S1. Pak se to provede stejným způsobem jako u zbývajících pěti segmentů.
Sekvence studie je následující:
-Analyzujte výsledky průzkumu, které jsou poté diskutovány, a analyzujte výsledky podle segmentů.
-Proveďte srovnání mezi výsledky podle segmentů.
-Nakonec vytvořte hypotézy, které vysvětlují příčiny těchto výsledků..
V našem příkladu, ve kterém uplatňujeme vzorkování pomocí kvót, je nejprve třeba stanovit kvóty a poté provést studii. Tyto kvóty samozřejmě nejsou vůbec rozmarné, protože byly založeny na předchozích statistických informacích o celkové populaci..
Pokud nemáte předchozí informace o studované populaci, je lepší obrátit postup, to znamená nejprve definovat velikost vzorku a po stanovení velikosti vzorku pokračovat v aplikaci průzkumu náhodným způsobem.
Jedním ze způsobů, jak zajistit náhodnost, by bylo použití generátoru náhodných čísel a dotazování zaměstnanců, jejichž počet zaměstnanců odpovídá počtu generátorů náhodných čísel..
Jakmile jsou údaje k dispozici, a protože cílem studie je vidět úrovně úzkosti podle věkových a pohlavních vrstev, jsou data rozdělena podle šesti kategorií, které jsme dříve definovali. Ale bez stanovení jakéhokoli předchozího poplatku.
Z tohoto důvodu je metoda stratifikovaný náhodný výběr považuje se to za pravděpodobnostní metodu. Mezitím on vzorkování kvót dříve zřízené č.
Pokud jsou však kvóty stanoveny s informacemi založenými na statistikách populace, pak lze říci, že metoda vzorkování kvót je zhruba pravděpodobné.
Navrhuje se toto cvičení:
Na střední škole chcete udělat průzkum o preferencích mezi studiem přírodních věd nebo humanitních věd.
Předpokládejme, že škola má celkem 1 000 studentů seskupených do pěti úrovní podle roku studia. Je známo, že v prvním ročníku studuje 350 studentů, ve druhém 300, ve třetím 200, ve čtvrtém 100 a nakonec v pátém ročníku 50. Je také známo, že 55% studentů školy jsou chlapci a 45% dívky..
Určete vrstvy a kvóty podle vrstvy, abyste věděli, kolik průzkumů se má použít podle roku studia a pohlaví. Dále předpokládejme, že vzorek bude 10% z celkové populace studentů..



Zatím žádné komentáře